Real time data processing at the source is required for edge computing with reduced latency for Internet of Things (IoT) and 5G networks as they use cloud.
To Harness Generative AI, You Must Learn About “Training” & “Inference”
by
GIGABYTE
Unless you’ve been living under a rock, you must be familiar with the “magic” of generative AI: how chatbots like ChatGPT can compose anything from love letters to sonnets, and how text-to-image models like Stable Diffusion can render art based on text prompts. The truth is, generative AI is not only easy to make sense of, but also a cinch to work with. In our latest Tech Guide, we dissect the “training” and “inference” processes behind generative AI, and we recommend total solutions from GIGABYTE Technology that’ll enable you to harness its full potential.
Generative AI is not actually a robot holding a paintbrush, of course. But this evocative image represents how endearing, capable, and inspiring the future of AI can be.
Rather than rehashing the prowess of generative AI, we will go ahead and pull back the curtain: all of generative AI boils down to two essential processes called “training” and “inference”. Once you understand how they work, you’ll be in a solid position to make them work for you.
Let’s use the chatbot, ChatGPT, as an example. The “T” in “GPT” stands for transformer, which is an architecture used by a subset of natural language processing (NLP) called large language model, or LLM for short. LLM has become the predominant way to teach computers to read and write like humans do, because it is able to “train” itself on a large corpus of unlabeled text (we’re talking about a word count that’s in the trillions) through deep learning and artificial neural network (ANN) technology. To put it in simpler terms, it has taught itself to read and write by wading through the equivalent of the entire Wikipedia, and so it is able to converse on just about any topic. The part where it draws upon its past training to respond to your queries is called “inference”.
Okay, so how does Stable Diffusion or Midjourney or any one of the myriad text-to-image models work? Not so different from ChatGPT, really, except this time there’s a generative image model attached to the language model. These models were also trained on a large body of digital texts and images, so that the AI can convert image to text, (using words to describe what’s in a picture), or vice versa, (drawing what you asked it to draw). The tactful injection of masking or blurring to make the final work more appealing should feel like second nature to anyone who’s ever taken a selfie on a smartphone. Put enough effort into giving the AI the right prompts, and it should come as no surprise that AI-generated art has won blue ribbons in art contests.
Now that we’ve shown you the nuts and bolts of how the most popular forms of generative AI operate, let’s go deeper into the technologies involved and the tools that you’ll need to make this exciting new breakthrough in artificial intelligence work for you.《Glossary: What is Artificial Intelligence?》
Training: How It Works, Which Tools to Use, and How GIGABYTE Can Help
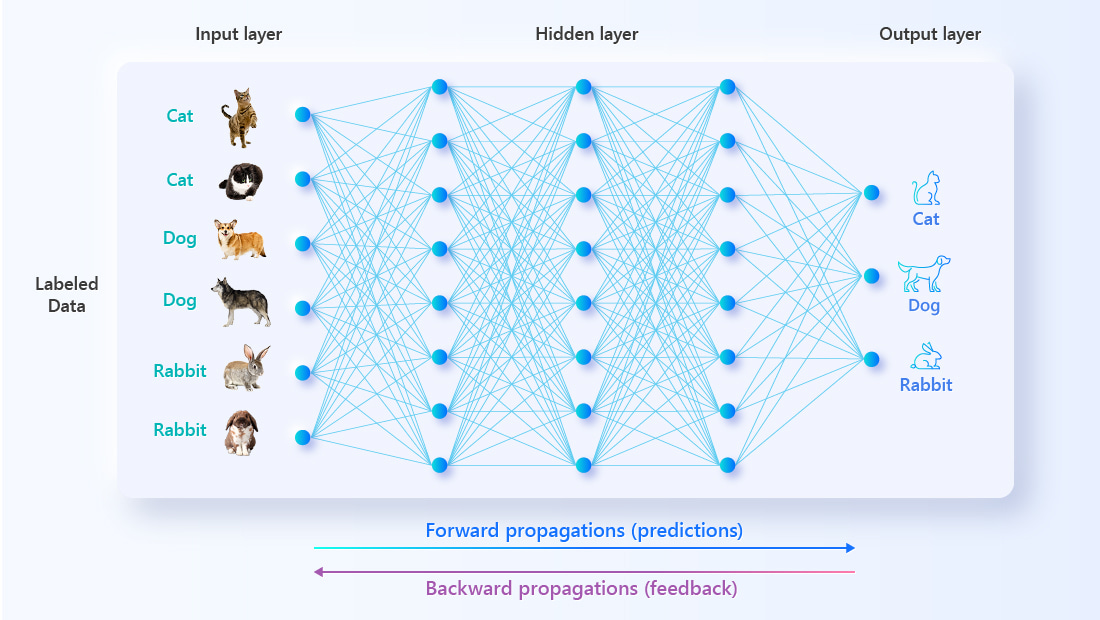
There’s a reason why the modern field of machine learning leans heavily into neuroscientific terminology—this branch of AI development benefits greatly from our understanding of the human brain. To wit, humans have billions of neurons in our brains that communicate with each other by forming trillions of synapses. The ANN is also made up of layers and layers of nodes that are modeled on biological neurons; the connections between them are akin to our synapses.
When a piece of datum passes from layer to layer, a weighted score is assigned to the data parameters depending on the validity of the output. Through repeated iterations of predictions (forward propagations) and feedback (backward propagations), the weightings become so precise that the right connections will always be chosen. To employ a rough analogy, you may think of it as the previously analyzed data leaving “grooves” in the algorithm for future data to follow. So, even though the AI doesn’t understand your commands in a literal sense, it’s practiced guessing for such a long time on so much data, it can generate an educated response to new input, whether it’s in the form of texts or images.
Typically, during the AI training process, a sea of labeled data is poured into the algorithm for it to “study”. The AI makes guesses and then checks the answers to improve its accuracy. Over time, the AI becomes so good at guessing that it’ll always make the correct guess; in other words, it’s “learned” the information that you wanted it to work with.
Without question, big data—the massive volume of data that our interconnected electronic devices are collecting on a daily basis—was a great help in making sure that the AI had a wealth of information to learn from. Earlier methods of training relied on “labeled” data and were supervised by human programmers—which is to say, a lot of hand-holding was necessary. But recent advancements have made it possible for the AI to engage in self-supervised or semi-supervised learning using unlabeled data, greatly expediting the process.《Glossary: What is Big Data?》
Needless to say, the scope of computing resources required to train the AI is not only breathtaking, but also ramping up exponentially. For example, GPT-1, which was released in 2018, trained for “one month on 8 GPUs”, using up approximately 0.96 petaflop/s-days (pfs-days) of resources. GPT-3, which was released in 2020, used up 3,630 pfs-days of resources. Numbers are not available for the current iteration of GPT-4, but there’s no doubt that the time and computing involved were greater than GPT-3 by orders of magnitude.《Glossary: What is GPU?》
Therefore, if you want to engage in AI training, what you need is a powerful GPU computing platform. GPUs are preferred because they excel at dealing with a large amount of data through parallel computing. Thanks to parallelization, the aforementioned transformer architecture can process all the sequential data that you feed it all at once. For the discerning AI expert, even the type of cores within the GPU can make a difference, if the aim is to further whittle down the time that it takes to train the AI.
GIGABYTE’s G593-SD0 and G593-ZD2 integrate the most advanced 4th Generation Intel® Xeon® and AMD EPYC™ 9004 CPUs, respectively, with NVIDIA’s HGX™ H100 computing module inside a 5U chassis. This is one of the most powerful AI computing platforms on the planet, and it can be the linchpin in your AI training setup.
Currently, one of the most advanced AI computing platforms in the world is GIGABYTE’s G-Series GPU Servers. The most advanced of these servers combine AMD EPYC™ 9004 processors (in the case of the G593-ZD2) or 4th Gen Intel® Xeon® Scalable processors (G593-SD0) with the HGX™ H100 computing module by NVIDIA. The HGX™ H100 can house up to eight H100 GPUs; these cutting-edge accelerators are built around NVIDIA’s 4th generation Tensor Cores, which are especially suited for deep learning, and they offer a dedicated “Transformer Engine” with FP8 precision, which can speed up LLM training. The HGX™ H100 delivers over 32 petaFLOPS of AI performance when it’s loaded with all eight GPUs. GIGABYTE was able to fit all this processing prowess into a 5U server thanks to its proprietary cooling tech and chassis design, so that customers can enjoy incredible compute density with a minimal footprint.
It is important to note that AI training has been going on long before generative AI came on the scene. Clients who develop AI models often elect to purchase GIGABYTE’s industry-leading G-Series GPU Servers. For instance, a world-famous Israeli developer of autonomous vehicles uses the G291-281 to train its fleet of self-driving cars. The Institute for Cross-Disciplinary Physics and Complex Systems (IFISC) in Spain utilizes the G482-Z54 to monitor Europe’s treasured olive groves with satellite imagery and AI. In 2020, a supercomputing team from Taiwan’s Cheng Kung University (NCKU) used GIGABYTE’s G482-Z50 servers to break the world record for BERT, a language model based on the transformer architecture.
Server solutions aren’t the only products that GIGABYTE has to offer for AI training. The DNN Training Appliance is a software and hardware package that combines powerful computing with a user-friendly GUI. It provides developers with the ideal environment to manage datasets, monitor the system in real time, and engage in AI model analysis.
Inference: How It Works, Which Tools to Use, and How GIGABYTE Can Help
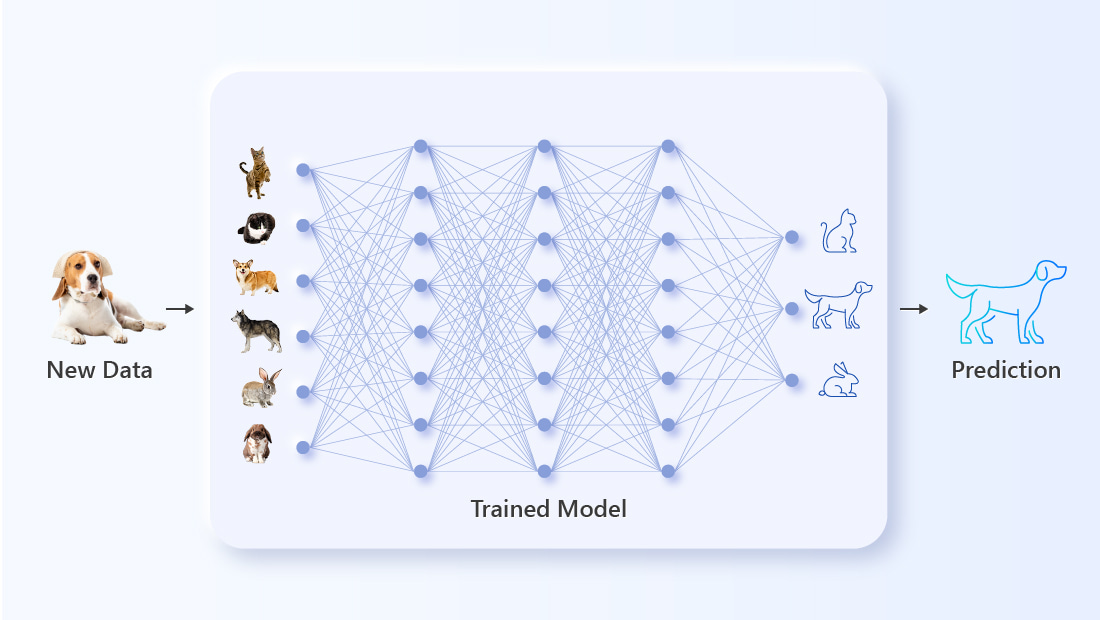
Once the AI has been properly trained and tested, it’s time to move on to the inference phase. The AI is exposed to a deluge of unfamiliar new data to see if it sinks or swims. In the case of generative AI, this could mean anything from requests to write an essay about inner-city crime on Pluto to demands that it paint a picture of an astronaut on a horse in the style of the nineteenth-century Japanese artist Utagawa Hiroshige (don’t ask why).
The AI compares the parameters of these new inputs to what it’s “learned” during its extensive training process and generates the appropriate output. While these forward and backward propagations are being shunted between the layers, something else interesting is happening, as well. The AI is compiling the responses it receives from the human users for its next training session. It takes note when it is praised for a job well done, and it is especially attentive when the human criticizes its output. This continuous loop of training and inferencing is what’s making artificial intelligence smarter and more lifelike every day.
During the AI inference process, unfamiliar, unlabeled input is fed into the pre-trained model. The AI compares the parameters of the new data to its training and tries to make the correct prediction. Successes and failures during the inference phase are used in the next training session to further improve the AI.
Computing resources and GPU acceleration are still important when it comes to inferencing, but now there’s another wrinkle to consider: latency. Users demand fast replies from the AI, especially when a lot of the AI-generated content still need to be fine-tuned before they can be of any value. In other scenarios outside of generative AI, a speedy response may affect productivity or even safety, (such as when computer vision is employed to sort through mail or navigate a self-driving mail truck), so it is even more imperative to minimize latency.
One of the best GIGABYTE solutions for AI inference is the G293-Z43, which houses a highly dense configuration of inference accelerators, with sixteen AMD Alveo™ V70 cards installed in a 2U chassis. Alveo™ V70 is based on AMD’s XDNA™ architecture, which is optimized for AI inference. The adaptive dataflow architecture allows information to pass between the layers of an AI model without having to rely on external memory. This has the effect of improving performance and energy efficiency while also lowering latency.
Other highly recommended solutions for AI inference include the Qualcomm® Cloud AI 100, which can facilitate the ability of data centers to engage in inferencing on the edge more effectively, because it addresses several unique requirements of cloud computing, such as signal processing, power efficiency, node advancement, and scalability. These solutions for inference can be deployed in many of GIGABYTE’s server products—in addition to the G-Series GPU Servers, there are the E-Series Edge Servers and R-Series Rack Servers, among others.
GIGABYTE’s G293-Z43 provides an industry-leading ultra-high density of sixteen AMD Alveo™ V70 Inference Accelerator Cards in a compact 2U chassis. This setup offers surpassing performance and energy efficiency, as well as lower latency. Such a dense configuration is made possible by GIGABYTE’s proprietary server cooling technology.
Generative AI is finding its way into more and more aspects of our lives, from retail and manufacturing to healthcare and banking. At the end of the day, the server solutions you choose depends on which part of the generative AI journey you’d like to give a boost to—whether it’s processing data to “train” your AI, or the deployment of the AI model so that it can “inference” in the real world. The prowess of new AI inventions won’t seem so unreachable once you understand that there are a plethora of dedicated tools designed for working with them—from something as minute as the architecture of processor cores, to something as comprehensive as GIGABYTE Technology’s total solutions. The instruments for achieving success are in place. All you need to do is reach out and discover how artificial intelligence can “Upgrade Your Life”.
Thank you for reading GIGABYTE’s Tech Guide on “Generative AI: Training & Inference”. We hope this article has been helpful and informative. For further consultation on how you can benefit from AI in your business strategy, academic research, or public policy, we welcome you to reach out to our sales representatives at marketing@gigacomputing.com.