Real time data processing at the source is required for edge computing with reduced latency for Internet of Things (IoT) and 5G networks as they use cloud.
How to Pick the Right Server for AI? Part One: CPU & GPU
by
GIGABYTE
With the advent of generative AI and other practical applications of artificial intelligence, the procurement of “AI servers” has become a priority for industries ranging from automotive to healthcare, and for academic and public institutions alike. In GIGABYTE Technology’s latest Tech Guide, we take you step by step through the eight key components of an AI server, starting with the two most important building blocks: CPU and GPU. Picking the right processors will jumpstart your supercomputing platform and expedite your AI-related computing workloads.
Readers with their fingers on the vibrant pulse of cutting-edge technology will have observed that the induction of the “AI server” into the IT mix has become a priority for organizations across a wide spectrum, whether they work in the public or private sector, whether they’re focused on academics, research, manufacturing, or services. It is no wonder—artificial intelligence has proven to be a “force multiplier” in every field. To demonstrate with a few examples, generative AI can help with marketing, record-keeping, and customer relations, while other AI inventions like computer vision can improve productivity and efficiency in facilities as diverse as a distribution center or a highway toll station. For a majority of companies and institutions, it is no longer a question of “if” an AI server should be purchased, but “which one” should be purchased to make sure that it can live up to expectations.
GIGABYTE Technology, an industry leader in AI and high-performance computing (HPC) server solutions, has put together this Tech Guide to walk you through the steps of choosing a suitable AI server. In Part One of this two-part article, we will focus on CPU and GPU, the two processor products that are key to an AI server. We will advise you on which server processors correspond to your specific needs, and how you can make a smart decision that will add a powerful supercomputing AI platform to your tool kit.
Our analysis begins, as all dissertations about servers must, with the central processing units (CPUs) that are the heart and soul of all computers. The CPU is the main “calculator” that receives commands from the user and completes the “instruction cycles” that will deliver the desired results. Therefore, a large part of what makes an AI server so powerful is the CPU that’s at the center of it.
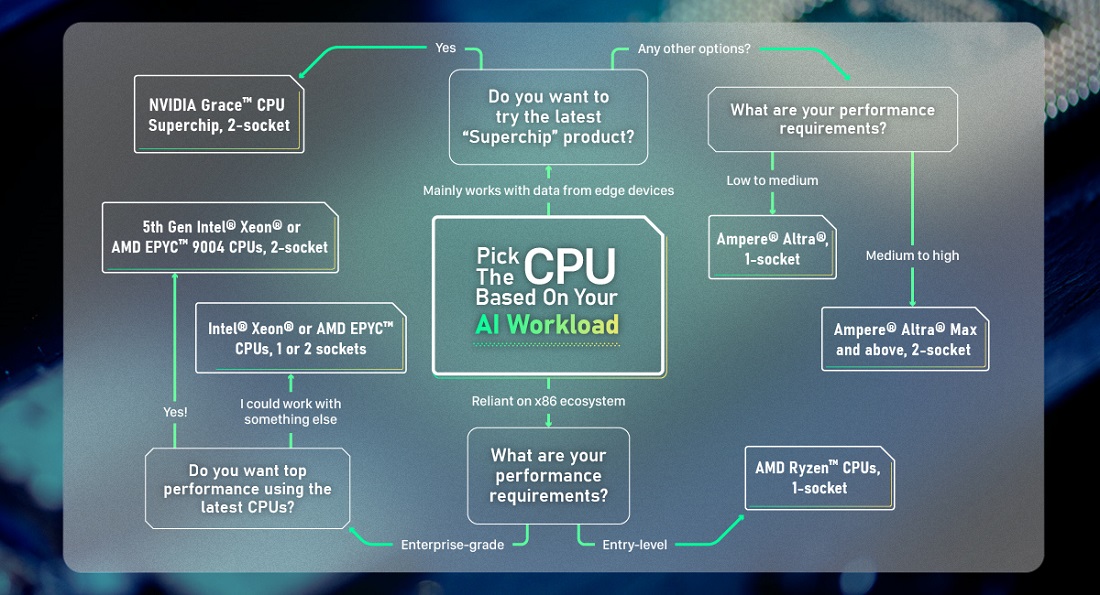
Those of you who are familiar with the current offerings might expect to see a point-by-point comparison between AMD and Intel CPUs, but it’s more complicated than that. True, these two industry leaders stand at the forefront of the CPU business, with Intel’s line of 5th Gen Intel® Xeon® CPUs and AMD’s line of AMD EPYC™ 9004 CPUs representing the pinnacle of CISC-based x86 processors. If you’re looking for excellent performance paired with a mature, tried-and-true ecosystem, you cannot go wrong with either of these chip manufacturers’ topline products. Or, if budget is a concern, you can consider older iterations of Intel® Xeon® and AMD EPYC™ CPUs. AMD’s Ryzen™ series is also a good entry-level choice if your AI workload can get by with a smaller number of cores and more limited multithreading capabilities.
But in the ever-expanding AI landscape, there are other choices besides AMD and Intel. RISC-based CPUs have become a serious contender in the supercomputing arena. The more simplified instruction set architecture (ISA) adopted by RISC processors means that they consume less power while containing more cores, allowing them to demonstrate computing prowess on par with their x86 counterparts. The fact that almost all mobile and edge devices (read: your smartphone) run on RISC chips means that RISC-based CPUs have the additional benefit of being “cloud-native”—that is, they don’t need a compiler to translate the data gathered by devices in the field. Therefore, if your AI workload involves data that comes from mobile and edge devices, you might consider giving RISC products a shot.
One of the most famous lines of RISC-based CPUs is ARM. GIGABYTE has an extensive range of ARM Servers powered by CPUs that are built by Ampere. The most advanced Ampere® CPUs contain around 200 cores in a single processor, while also providing best-in-class performance-to-watt ratio, which really helps to drive down TCO. Another exciting new addition to the ARM lineup is the NVIDIA Grace™ CPU Superchip, which combines ARM cores with patented NVIDIA features, such as 900GB/s NVLink-C2C Interconnect and world-first LPDDR5X with error-correcting code (ECC) memory. If you often work with NVIDIA’s AI software suite and would like to adopt its CPU hardware, GIGABYTE’s H263-V60 High Density Server is the AI supercomputing platform for you.
At this point, it only remains to decide whether you want one or two CPU sockets in your server. The highly dense configuration of two CPU sockets generally offers better performance and availability, at the cost of higher power consumption—and by extension, more demanding thermal management. If that’s an issue, you may consider the single-socket variation, so long as there are enough cores in the CPU to satisfy your AI computing requirements.
While not exhaustive, this flowchart should give you a good idea of which CPU set-up is best for your AI workload.
How to Pick the Right GPU for Your AI Server?
The deuteragonist in an AI server is the graphics processing unit, or GPU. They serve as accelerators that can help the CPU deal with AI workloads much, much faster. The reason is that GPUs are equipped with the simplified versions of the CPU’s toolbox, but in vastly larger numbers. The upshot is that a GPU can break a task down into smaller segments and process them concurrently though parallel computing—especially if the workload consists of graphical data, which is often the case when it comes to AI.
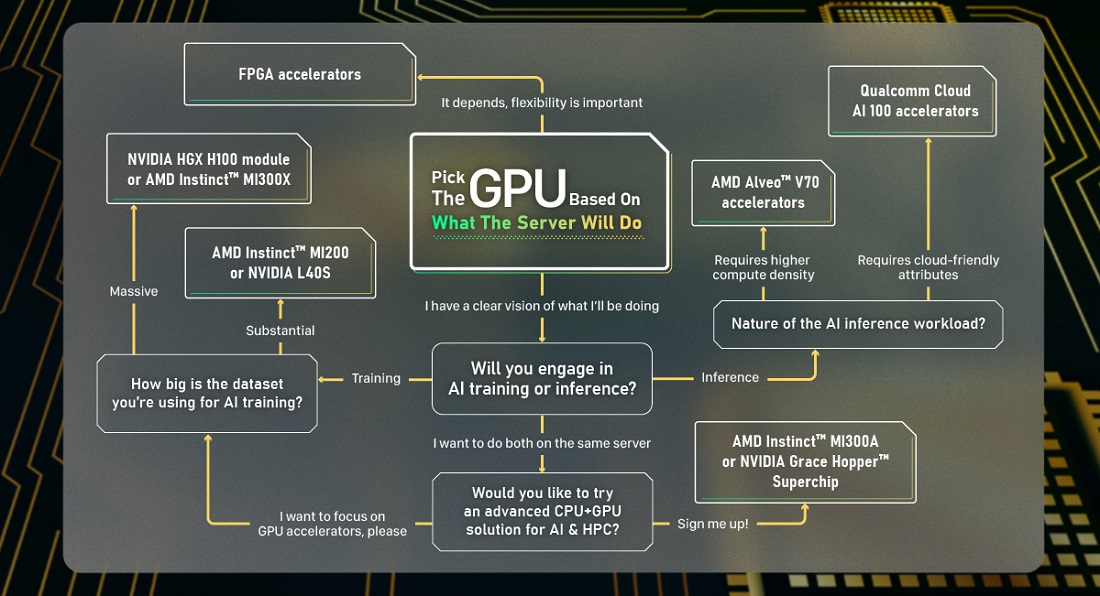
When choosing GPUs for your AI server, you can help to narrow the field by asking yourself: is the nature of my AI workload likely to change drastically over time? Most modern GPUs are designed for very specific tasks. Their chip architecture may be suited for certain subsets of AI development or application. But if you want your server to exhibit the flexibility to deal with a diverse range of assignments, GPUs based on the FPGA (“field-programmable gate array”) configuration may be a better choice. Unlike their ASIC (“application-specific integrated circuit”) counterparts, FPGA chips can be reprogrammed after manufacturing to perform different functions. Xilinx, which has been acquired by AMD, was a renowned manufacturer of FPGA chips. Many GIGABYTE servers are compatible with FPGA accelerators.
The next question to consider is if you will mainly engage in AI training or inference. These two processes are the basis of all modern iterations of “limited memory” AI. During training, the AI model ingests a large amount of big data with billions, or even trillions of parameters. It adjusts the “weightings” of its algorithms until it can consistently generate the right output. During inference, the AI draws on the “memory” of its training to respond to new input in the real world. Both of these processes are very compute-intensive, and so GPU expansions cards and modules are installed to help speed things along.
For AI training, certain GPUs are built with specialized cores and “engines” that can streamline the process. A good example is NVIDIA HGX™ H100 8-GPU, which can deliver over 32 petaFLOPS of FP8 deep learning performance. This module is integrated in GIGABYTE’s G593-SD0, G593-SD2, and G593-ZD2 servers. There is also a variation of the module with four GPUs, called the NVIDIA HGX™ H100 4-GPU. It is integrated in GIGABYTE G363-SR0, which supports liquid cooling to unlock the chips’ full potential while upping the data center’sPUE. Each H100 SXM5 GPU contains fourth-generation Tensor Cores that use the new FP8 data type, as well as a “Transformer Engine” to optimize model training. NVLink®, which offers up to 900 GB/s of bandwidth, is used to connect the processors, while NVSwitch is used to coordinate the cluster.
AMD’s Instinct™ MI300X is a powerful alternative. Its specialty is its enormous memory and data throughput, which is important for generative AI workloads, such as what is seen in a large language model (LLM). This enables LLMs like Falcon-40, a model with 40 billion parameters, to run on a single MI300X accelerator. GIGABYTE G593-ZX1 features eight MI300X GPUs for cutting-edge performance in AI computing.
As always, if you must forgo a little performance to keep within budget constraints, or if the dataset you’re training the AI with is not so massive, you can consider other offerings from AMD and NVIDIA. GIGABYTE has a comprehensive line of solutions that support the AMD Instinct™ MI200 Series of accelerators. The NVIDIA L40S GPU, which is supported by GIGABYTE G493-SB0, G293-S40, G293-S41, and G293-S45, is also highly recommended for AI training. The R162-Z11 Rack Server is another good example of a versatile server that does not include a computing module, but has PCIe slots that can support up to three NVIDIA GPUs.
As GPUs are key to handling AI workloads, it is important to pick the right options based on your actual requirements.
For AI inference, try to look for GPUs with user scenario-specific advantages. For example, one of the best AI inference servers on the market is GIGABYTE G293-Z43, which houses a highly dense configuration of sixteen AMD Alveo™ V70 cards in a 2U chassis. These GPUs are based on AMD’s XDNA™ architecture, which is noted for its adaptive dataflow architecture that allows data to pass through the layers of an AI model without requiring external memory. This has the effect of improving performance and lowering latency, making G293-Z43 the ideal solution for highly demanding AI workloads. GIGABYTE servers with multiple PCIe Gen 4 (or above) expansion slots are also compatible with NVIDIA A2 Tensor Core GPUs and L4 Tensor Core GPUs, which are aimed at tackling AI inference workloads.
If your inference workload will primarily occur on the cloud, other attributes like power efficiency and signal processing may seal the deal. In this scenario, you might consider the Qualcomm® Cloud AI 100 GPUs, which can inference on the edge more effectively because they address the unique requirements of cloud computing. These accelerators can be deployed in many of GIGABYTE’s servers, including the G-Series GPU Servers, R-Series Rack Servers, and E-Series Edge Servers.
Last but not least, since the compute requirement for AI training is generally higher than for inference, most training servers can also be used for inference workloads. Another exhilarating trend spearheaded by industry leaders is a “CPU plus GPU” package that offers the best of both worlds for all categories of AI and HPC workloads. The NVIDIA Grace Hopper™ Superchip, which is available on GIGABYTE’s H223-V10 and H263-V11 High Density Servers, and AMD Instinct™ MI300A, AMD’s first data center-grade APU (accelerated processing unit) that’s available on GIGABYTE’s G383-R80, are both sterling examples of this new school of thought. Choose these products if you want to work with the most sophisticated supercomputing platform currently in existence.
Thank you for reading GIGABYTE’s Tech Guide on “How to Pick the Right Server for AI? Part One: CPU & GPU”. To learn more about how to pick the other components for an AI server, please read on to “Part Two: Memory, Storage, and More”. We hope this article has been helpful and informative. For further consultation on how you can benefit from AI in your business strategy, academic research, or public policy, we welcome you to reach out to our sales representatives at marketing@gigacomputing.com.